April 26th, 2022
Despite growing up here I’ve never done much exploring of the “interior” of East Sussex. Normally I just go for a walk along the coast in one direction of the other. Well, time to change that: a new programme of exploration is launched! The first mission is north to Bodium Castle and then to Robertsbridge.

A wood just outside Hastings
This was my favourite part of the walk, an unexpectedly lush wood just a few minutes from Hastings hospital.

Bodium Castle
Bodium Castle is basically what you get when you ask a five year old to draw a generic castle. It made a brief film appearance as “Swamp Castle” in Monty Python and the Holy Grail!

Robertsbridge high street
This was the most picturesque part of Robertsbridge, a small town on the Hastings-London train line. I’ve passed through it on the train loads of times but I don’t think this is the first time I’ve ventured into the town itself.
On the map I saw a “Robertsbridge Abbey” but what is left of the ruin is on private land and so a bit of a disappointment.
April 23rd, 2022
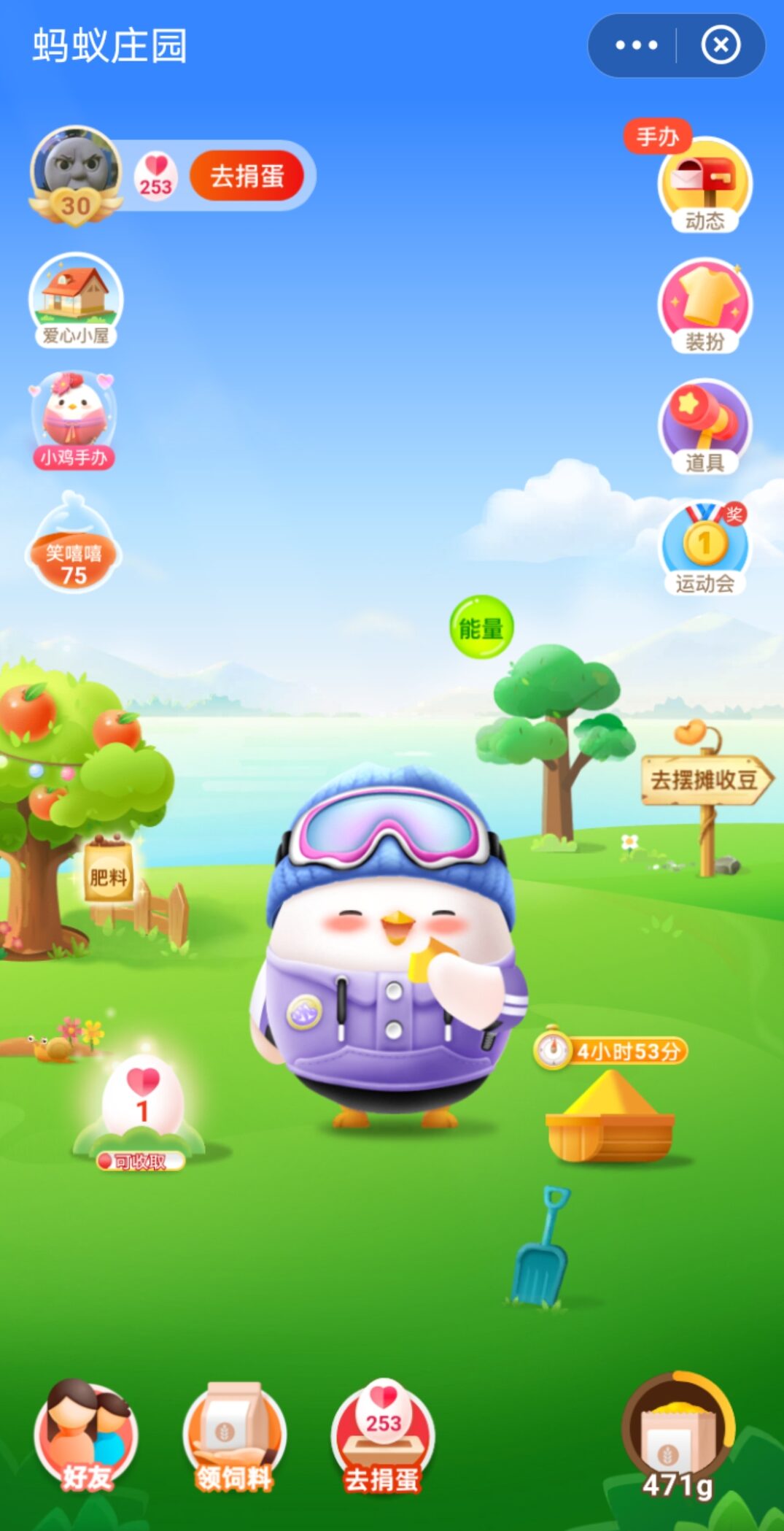
Sadly I’ve had to retire my “little chicken” that I’ve been feeding in the Alipay app for the last four years due to a lack of grain. I’ll just put a screenshot here to remember it:
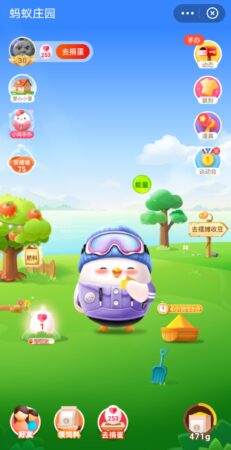
It’s a game of sorts where you collect grain either by buying things with Alipay or “engaging” with the app in some other way, then you feed the grain to the chicken and after a six hour gestation period it will emit an egg. You can then donate your egg to a charitable cause… or something like that. You can also play games with the chicken or dress it up in different outfits, like the stylish purple ski attire mine has. It’s all rather fun. Unfortunately when you don’t feed the chicken for a while it will start to make a nuisance of itself by invading your contacts’ farms and stealing their grain, so I’ve had to put an end to it.
April 23rd, 2022
Unseasonably warm and sunny weather on the Easter bank holiday weekend so I decided to go for a walk in the opposite direction along the coast.
The sea was eerily calm, almost like a lake. You can see in the miniscule waves in the picture below.

The rebuilt (and bankrupt) Hastings pier
I got to Bexhill and on a whim decided to divert to Sidley, site of my former sixth form college.

All that remains of Bexhill Sixth Form college
Alas the college has since been demolished: all that hints at its former existence is a residential estate named “Scholar’s Walk” and these old railings. Demolition is a common fate of educational institutions attend by me.

Sidley, but it could be anywhere really
Sidley is pretty nondescript. It doesn’t seem to have changed much in the last 18 years (I think the Aldi is new). I wouldn’t recommend a visit.
March 20th, 2022
I suppose I should feel honoured that my family’s ancestral hall has been commentated with this fine information board. However the building itself has seen better days and is not quite the fine palace I was imagining.

The heyday of our family beach hut

… and today’s sorry state
It’s just along the coast from Rye Harbour, which is somewhere I’ve visited many times, but I never saw the “ruin” before.

Mary Stanford lifeboat house
This is the “Mary Stanford” lifeboat house named after the lifeboat that used to be based here which tragically sunk in 1928 drowning all 17 crew.
Here’s the route I took along the coast:
March 18th, 2022
Back to Blighty and the weather is glorious! I totally forgot the sky could be this shade of blue. And where better to go than the local beach which festooned with these traditional fishing boats.

Oh how I missed the seagulls

Catchily named “RX142” (RX means “Rye” by the way)

“R4” and various bits of fishing junk
March 7th, 2022
Chongming island 崇明岛 is a large island on the north of the Yangtze estuary. And while it’s technically part of Shanghai it’s actually very rural and makes for an interesting day out.

Ferry to Chongming island
Getting there from the city is a bit convoluted. The quickest way is to take subway line 3 to Baoyang Road and take a bus to the ferry terminal of the same name. The ferry takes about 50 minutes and costs 16 RMB. Make sure you get the one to Nanmen 南门 as that’s the most touristy part.

Walking along the Yangtze river
I walked along the bank of the Yangtze river for a little way from the ferry terminal. It was really hazy. Might have been pollution but the air quality report that didn’t seem too bad…

Chongming academy
Next stop was Chongming Academy, an old Confucian school. Nothing spectacular to look at, but there’s some interesting exhibits (in Chinese) in several of the buildings about the history of Chongming island. Apparently it used to be an important centre of cloth production, and now it’s trying to reinvent itself as an ecotourism destination.
After that I took the bus to the wetland park in the north of the island. The bus trip is around an hour, which I wasn’t expecting, but the view along the way was interesting. One thing you’ll notice straight away is almost everyone on the island is old (quite common in rural China). The other noteworthy thing was the number of churches – I counted at least two plus some crosses on walls – which I hardly ever see on the mainland.

Harvested grass in the wetland park
With all the time spent travelling I only had time for two attractions but there’s also some temples and a forest park, so maybe you could make a weekend of it.
Here’s a pro tip: the last boat back to the mainland is at 6pm. If, like me, you miss this it’s also possible to take a long-distance bus back to the mainland via the bridge at the south of the island. The bus leaves from the bus station near the ferry terminal and takes about 1.5 hours to reach a subway station on line 6.
March 5th, 2022
A double day of sightseeing today in Qingpu district, which is in the far west of Shanghai. My first stop was Zhujiajiao ancient town. I didn’t have very high hopes considering the other old towns in the Shanghai suburbs have been over-commercialised and not very interesting, but this one was surprisingly quiet and well preserved. There are a couple of small paid exhibits including a garden, temple, and a craft museum.

Zhujiajiao ancient town
Next I rode all the way to the end of line 17 to try to get to Dianshan lake, Shanghai’s largest lake. I was going to walk there but thought better of it and got on a bus. The place you want to go to is called Xicai 西蔡 and there’s a long path around the lake with great views.

Dianshan lake
Years ago when I used take the train to Suzhou I was always fascinated by this massive skyscraper built seemingly in the middle of the countryside. I saw it again today on the other side of the lake. I still don’t know what it is. Only in China I suppose.

The mysterious tower
March 1st, 2022
Last week I took a trip up to the 100th floor observation gallery in the Shanghai World Financial Centre the second tallest building in Shanghai. For a time it was also the second tallest building in the world, but it’s a fair way down the rankings now.

It’s the one on the left that looks like a bottle opener
The 100th floor ticket costs 180 which is cheaper, higher, and less crowded than the Oriental Pearl Tower, so triple win. You can save 60 RMB by only going to the 94th floor, but why bother.

The observation deck is pretty empty
The best time to visit is around sunset on a clear day, that way you get both the day and night scenery. The gallery isn’t ideal for taking photos in the day time though because the windows have a lot of glare, and there’s no outside area like the Taipei 101.

Sunset with the ever present haze
February 27th, 2022
For a while now I’ve been searching for a simple lightweight text editor to use when editing configuration files as root and when SSH-ing to remote machine. My normal editor is GNU Emacs with 15+ years of accumulated baggage which makes it pretty slow to start up. I’ve tried the various workarounds like the Emacs daemon and TRAMP but it still feels like a lot of faff compared to just SSH and starting an editor. I’ve also tried nano and vi, but my Emacs muscle memory makes them too annoying to use.
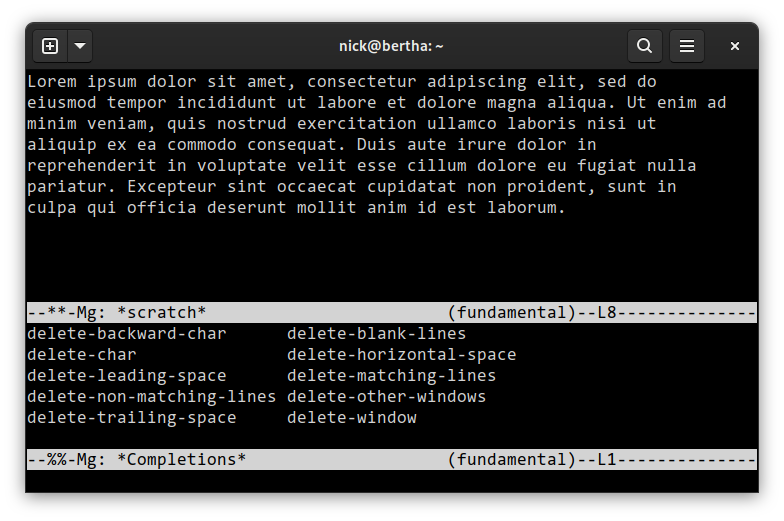
Recently I’ve settled on mg, a venerable Emacs clone that’s maintained as part of the OpenBSD base system and also available on Linux.
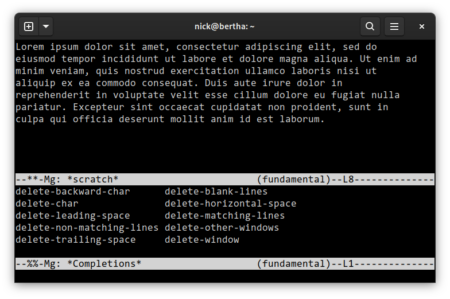
It starts up instantly and with the minor configuration tweaks below is pretty ergonomic.
global-set-key "\^z" undo
global-set-key "\^?" delete-backward-char
global-set-key "\^h" delete-backward-char
global-set-key "\e[1;3C" forward-word
global-set-key "\e[1;3D" backward-word
global-set-key "\e[1;5C" forward-word
global-set-key "\e[1;5D" backward-word
auto-execute *.c c-mode
auto-execute *.h c-mode
make-backup-files 0
set-default-mode indent
set-fill-column 72
February 25th, 2022
Not much here, just a photo, but it’s somewhat remarkable since I almost never come to the city centre since I moved here.

Probably the best thing you can do here is ride the yellow and white ferry. Zig-zag across on the different lines. It’s quite fun.






















































































































































 Posts
Posts